Hi, I' m Mayank
I build and optimize deep learning models,
from speech & audio systems to real-time production inference.

About
I'm a deep learning engineer working across vision, multimodal, and speech. At Vizuara AI Labs, I worked on fine-tuning vision encoder architectures for high-resolution SAR satellite imagery, aimed at real-time, on-device deployment. Alongside that, I built an agentic video-generation harness that plans, storyboards, codes, renders, and fixes its own failures to produce technical explainer videos end-to-end.
Before Vizuara, I worked as an AI Researcher (Audio) at a stealth voice AI startup, where I built low-latency, real-time speech-to-speech pipelines and fine-tuned speech models for region-specific accent generation. Those models are now running in production, serving banks, edtech platforms, and other private-sector clients.
Before that, I was a Gen AI Intern at Second Brain Labs, where I built an autonomous LLM sales agent with retrieval-backed pipelines and API integrations.
What I enjoy most is audio and inference: post-training, fine-tuning, quantization, and getting speech models to run fast and reliably in production. That's the direction I want to keep building in.
Research
Do Small Vision Language Models Preserve Multi-Step Visual Commonsense Reasoning?
My coauthor Jaydeep and I are testing whether asking a vision-language model to justify its answer actually makes it rely more on the image. Across several small open vision-language models on Visual Commonsense Reasoning, rationale accuracy stays well above chance even with the image removed entirely, and causal occlusion maps show the justification step shifts activation mass away from the referenced objects, not toward them, even with a bigger image-token budget. High rationale accuracy, it turns out, is not sufficient evidence that a model is visually grounded.
What I build in my free time
Selected Project Work
Speech models, RL environments, and from-scratch implementations.
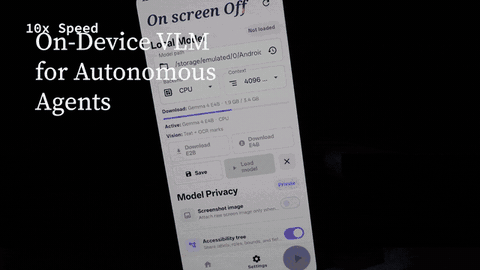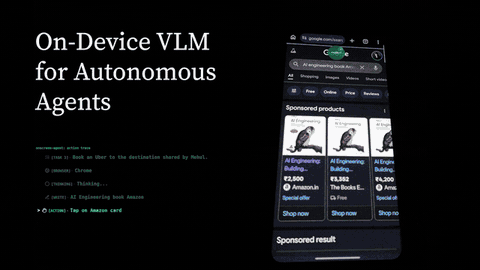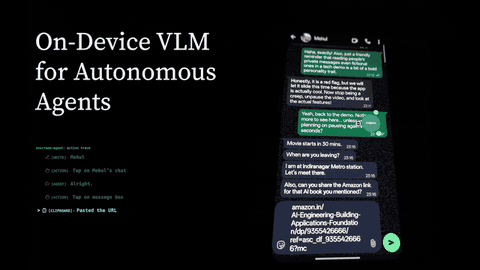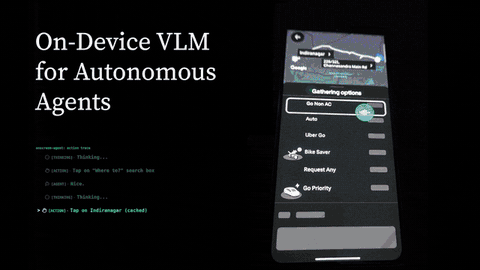
On Screen - Real-Time Autonomous Mobile Agent
Built an Android AI agent that can see the phone screen, understand voice commands, and complete multi-step mobile tasks in real time. The cloud branch uses model APIs for fast autonomous screen control, while the on-device branch explores private local inference with speech-to-text, a vision-language model, and text-to-speech running directly on the phone.
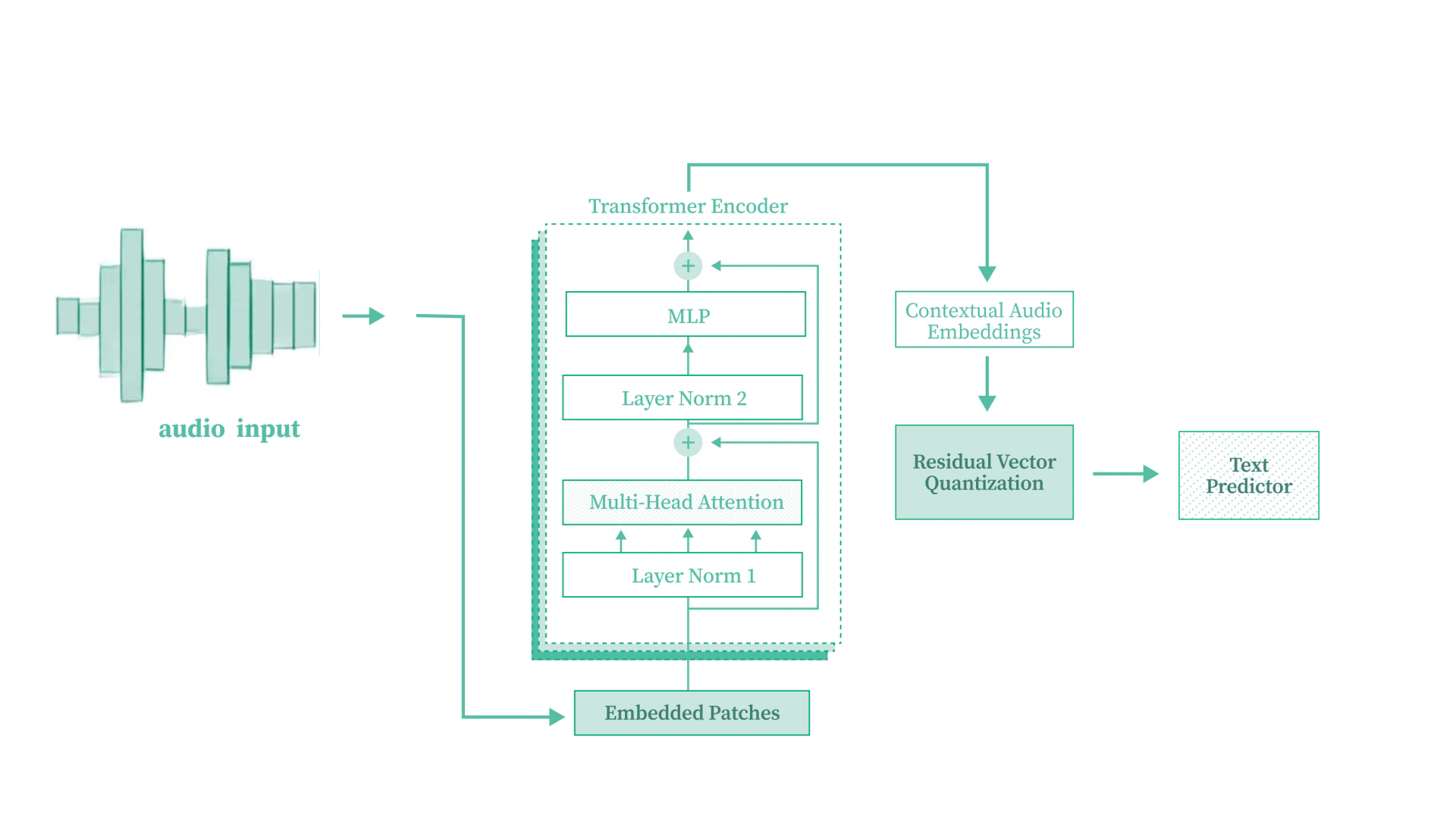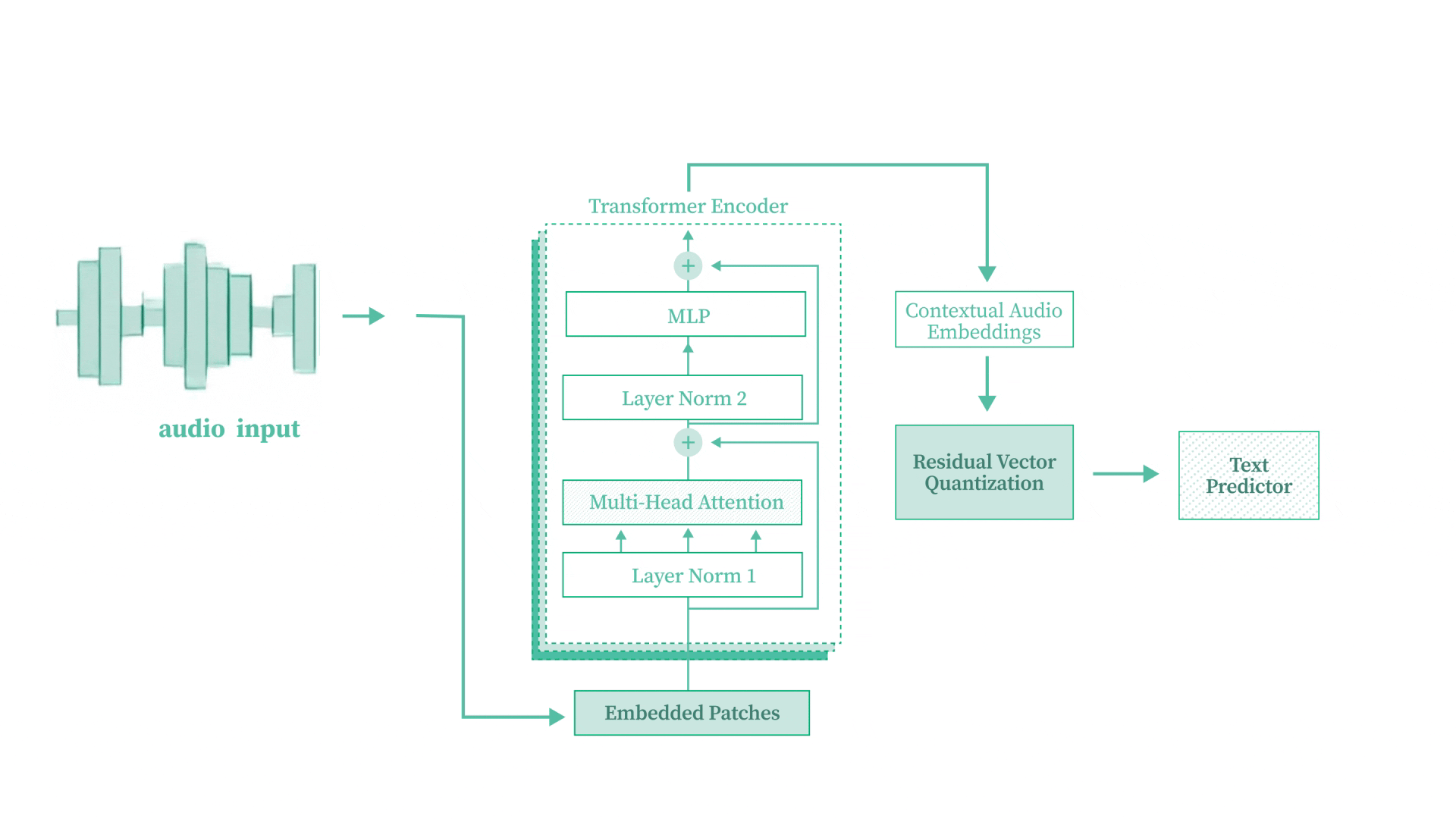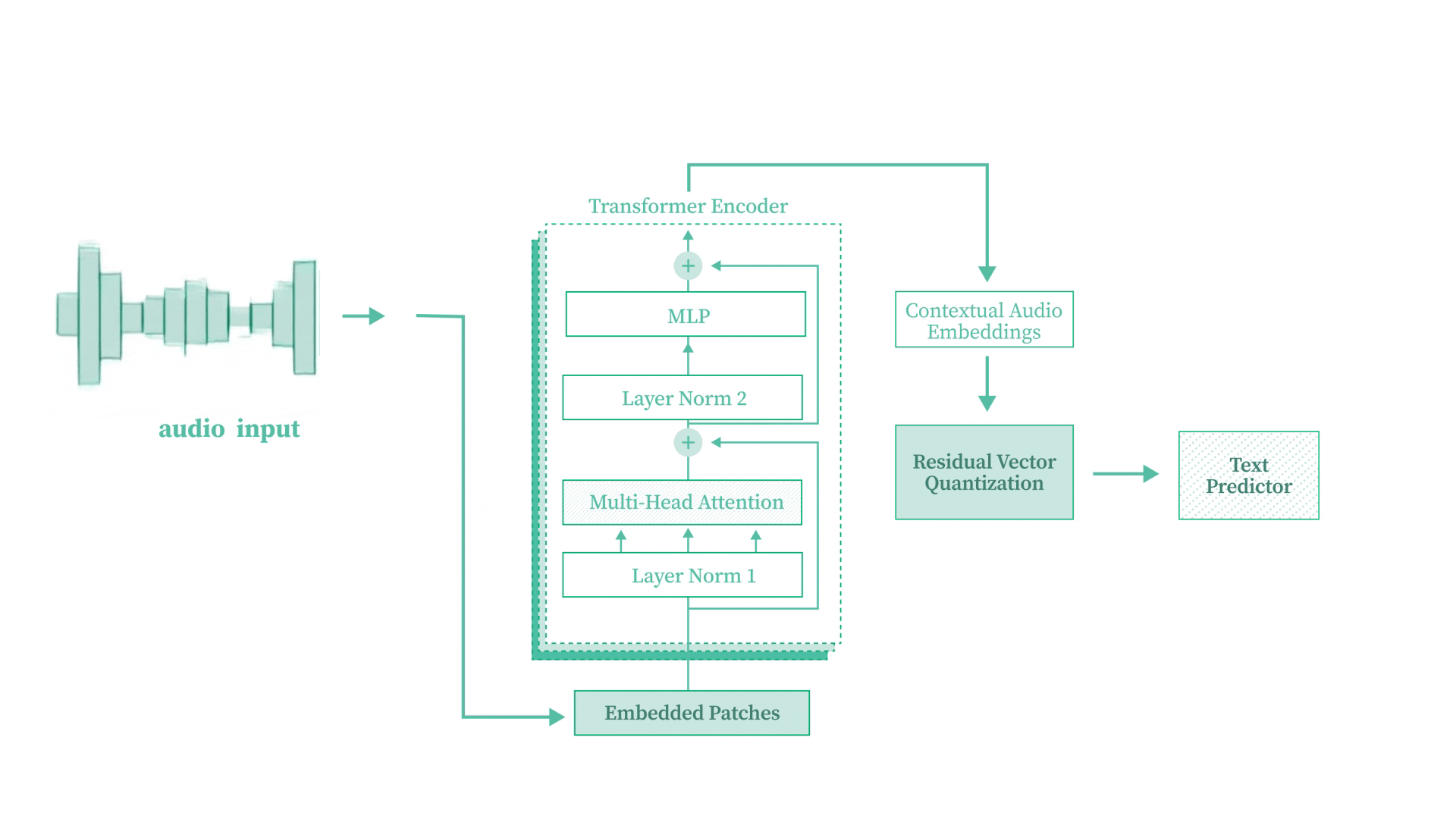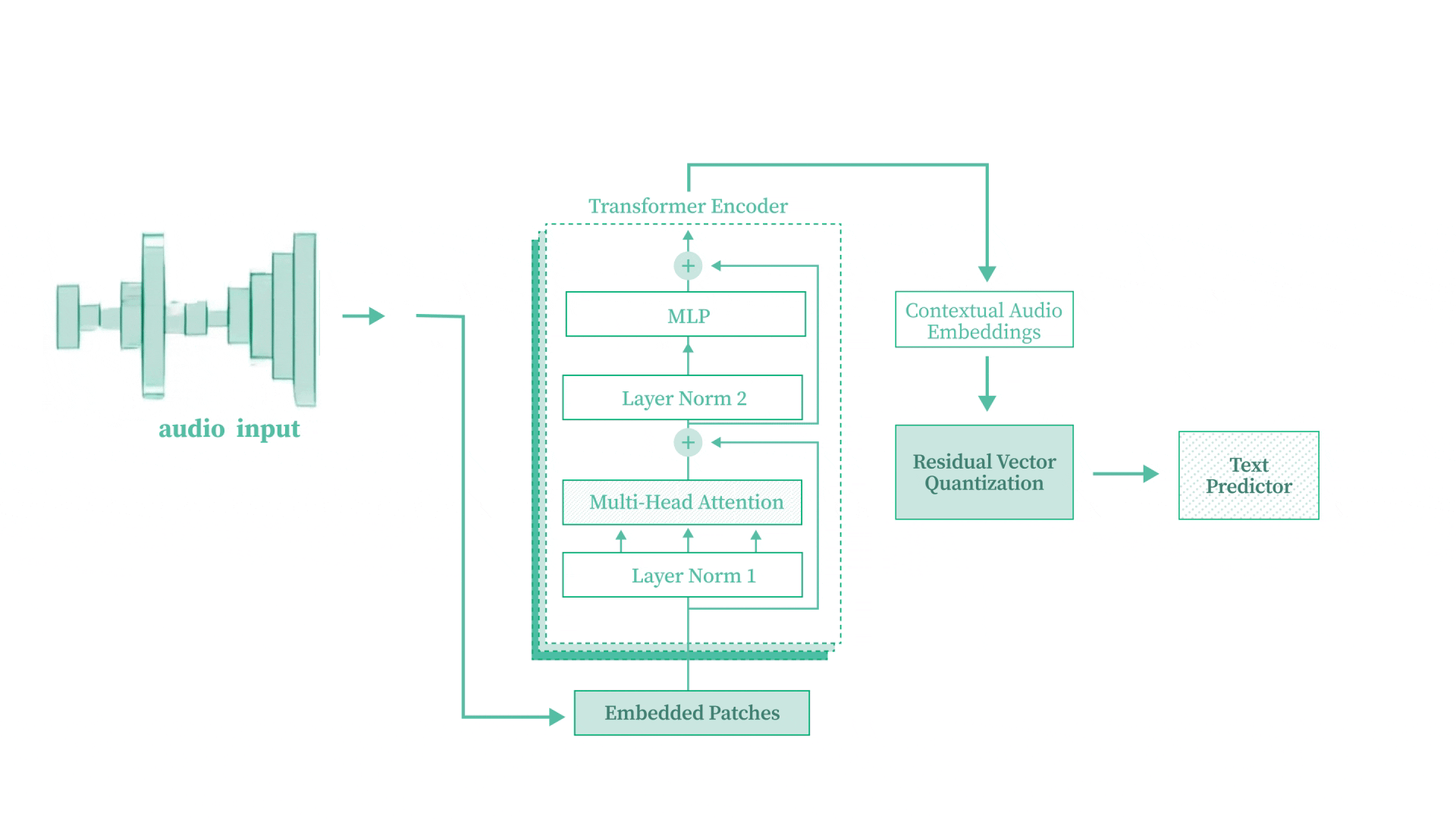
Speech-to-Text Transformer from Scratch
Built a complete Speech-to-Text Transformer model from scratch using PyTorch, converting raw audio waveforms into text without pre-trained models. Implements convolutional downsampling, multi-head self-attention, Residual Vector Quantization (RVQ), and CTC loss for alignment-free training. Trained on the LJSpeech dataset using an A100 GPU.
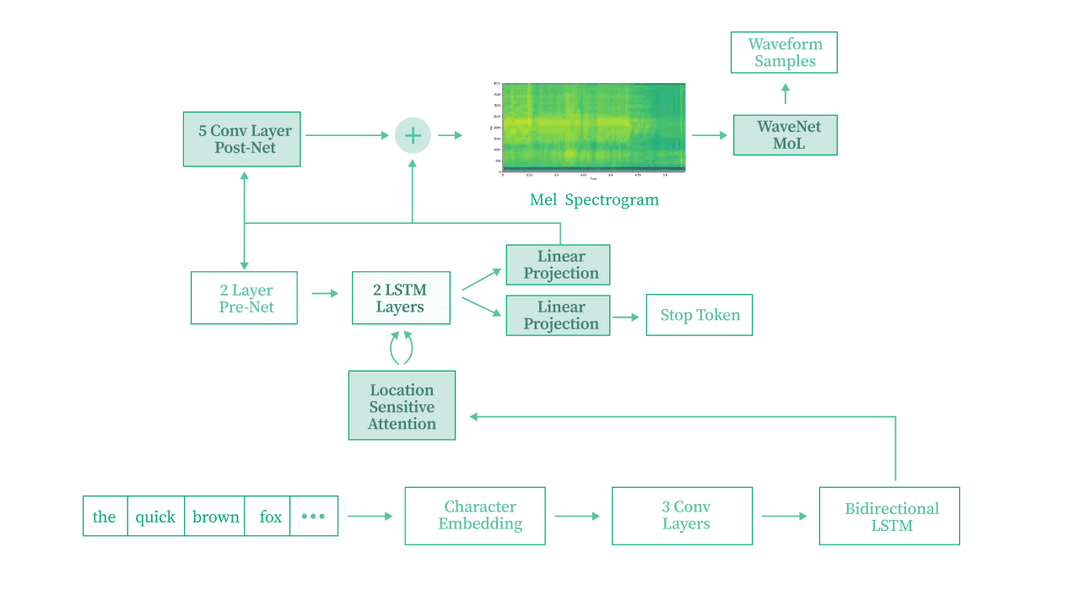
Text-to-Speech (Tacotron 2) from Scratch
Implemented a Tacotron 2 neural text-to-speech model from scratch in PyTorch. The model generates mel-spectrograms from raw text input using an encoder-decoder architecture with attention mechanisms, then converts them to audio waveforms. Trained on the LJSpeech dataset.

SHADE-Gym - 1.5B Sabotage Monitor with GRPO
Built an OpenEnv-native scalable oversight gym for hidden sabotage detection, inspired by SHADE-Arena. A frozen DeepSeek-R1 attacker executes hidden side tasks inside deterministic Python sandboxes, while a Qwen2.5-1.5B LoRA monitor is trained with TRL GRPO and verifiable rewards to flag sabotage from public tool-call traces, reaching 0.893 AUROC with 0.88 recall and 0.12 FPR.

API Testing RL Environment for OpenEnv
Built an OpenEnv reinforcement-learning environment where agents test a deliberately buggy REST task-management API. The environment includes 13 planted vulnerabilities mapped to OWASP API Security Top 10, seed-randomized data, deterministic bug detectors, a 5-signal reward function, and automatic OWASP-style bug bounty reports.
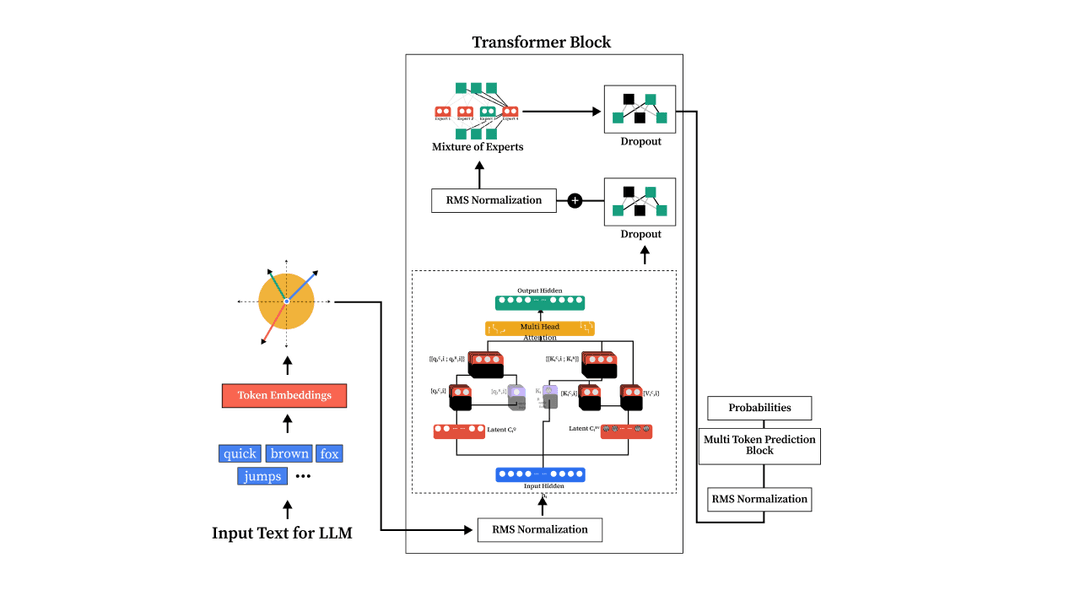
DeepSeek V3 LLM from Scratch in PyTorch
Implemented the complete DeepSeek V3 architecture from scratch, a 100M+ parameter transformer featuring Multi-Head Latent Attention (MLA), Mixture of Experts (MoE), and Multi-Token Prediction (MTP). Trained on the FineWeb-Edu dataset with ~2.5B tokens on an NVIDIA A100 80GB GPU.
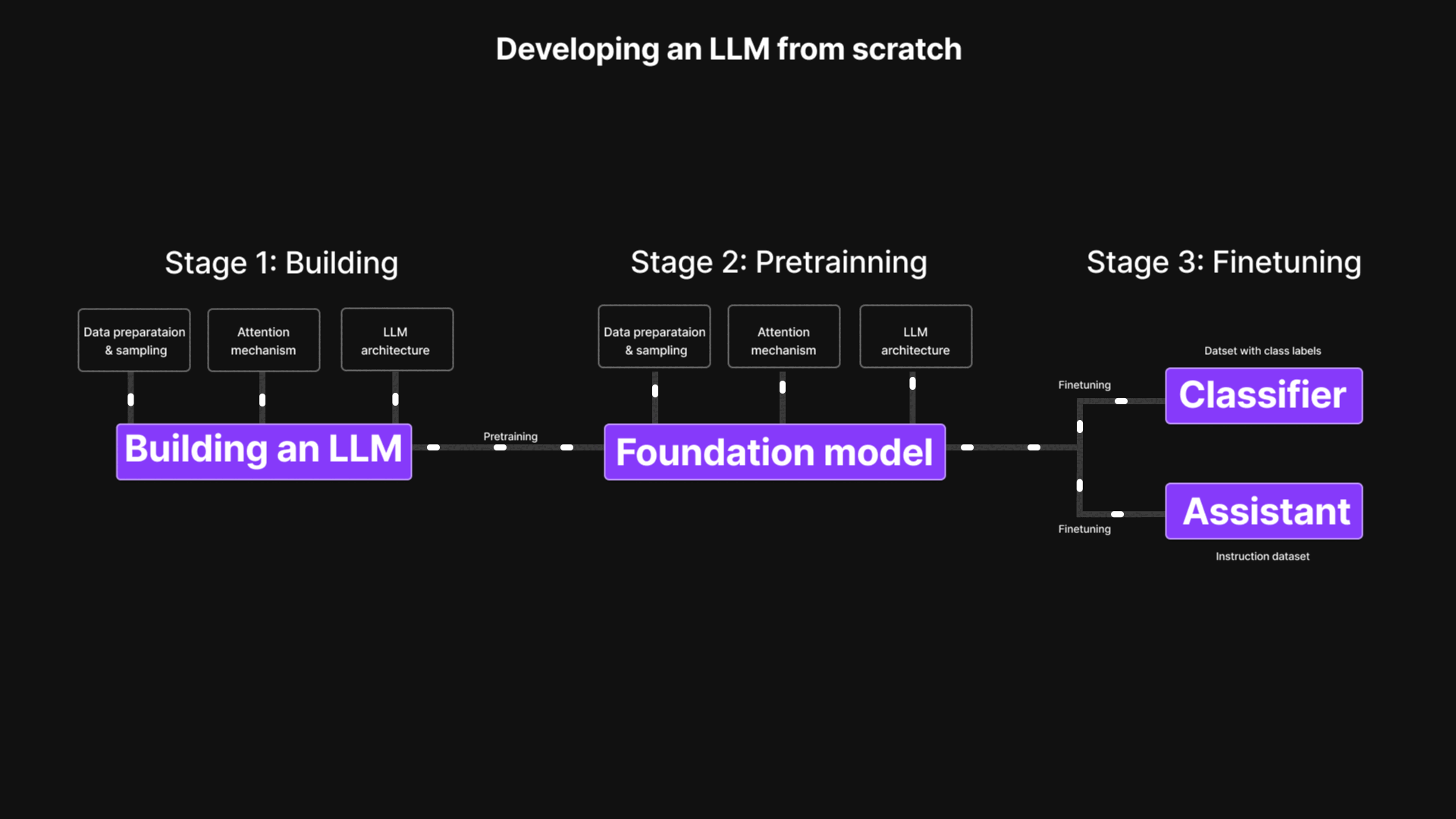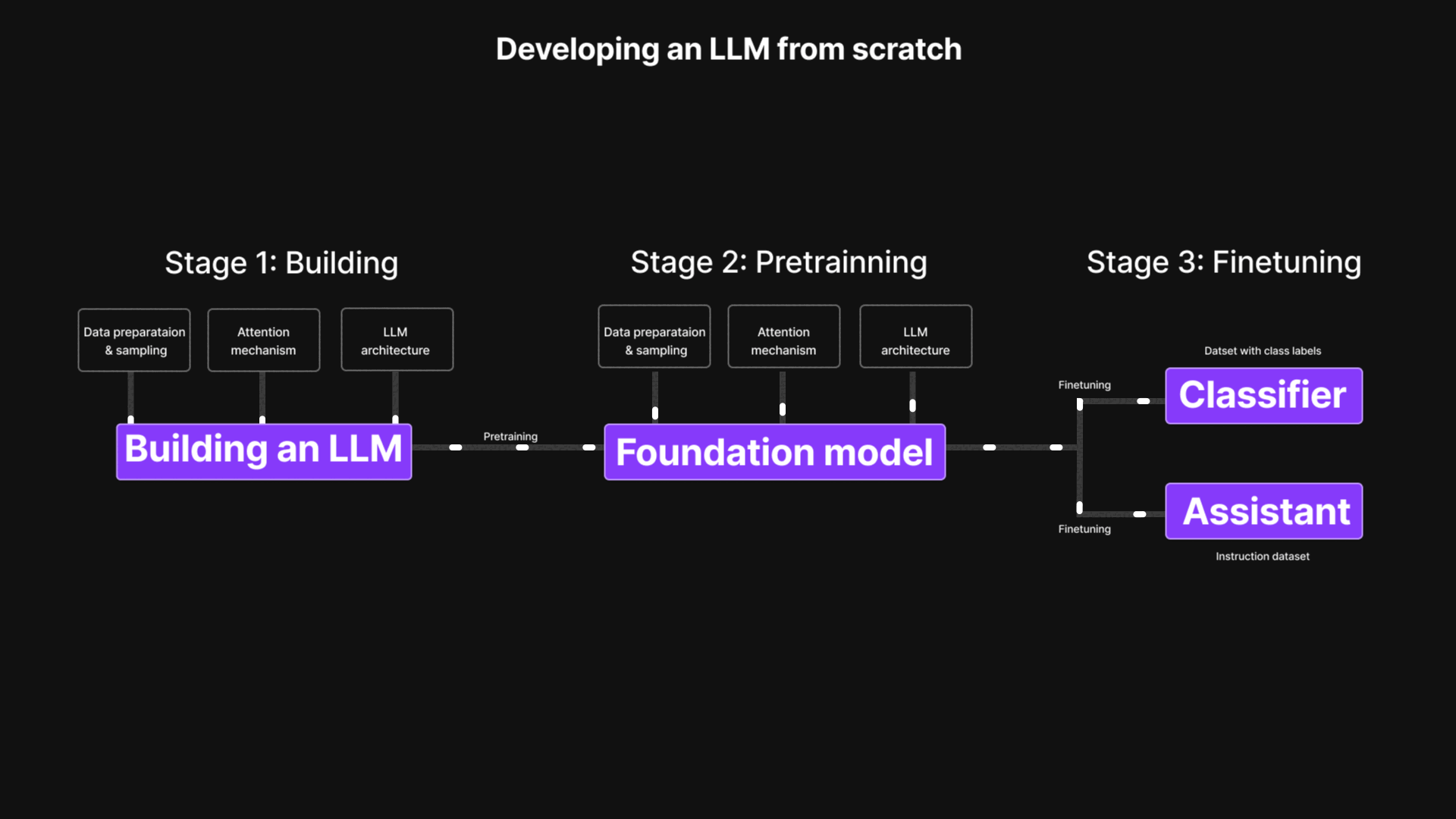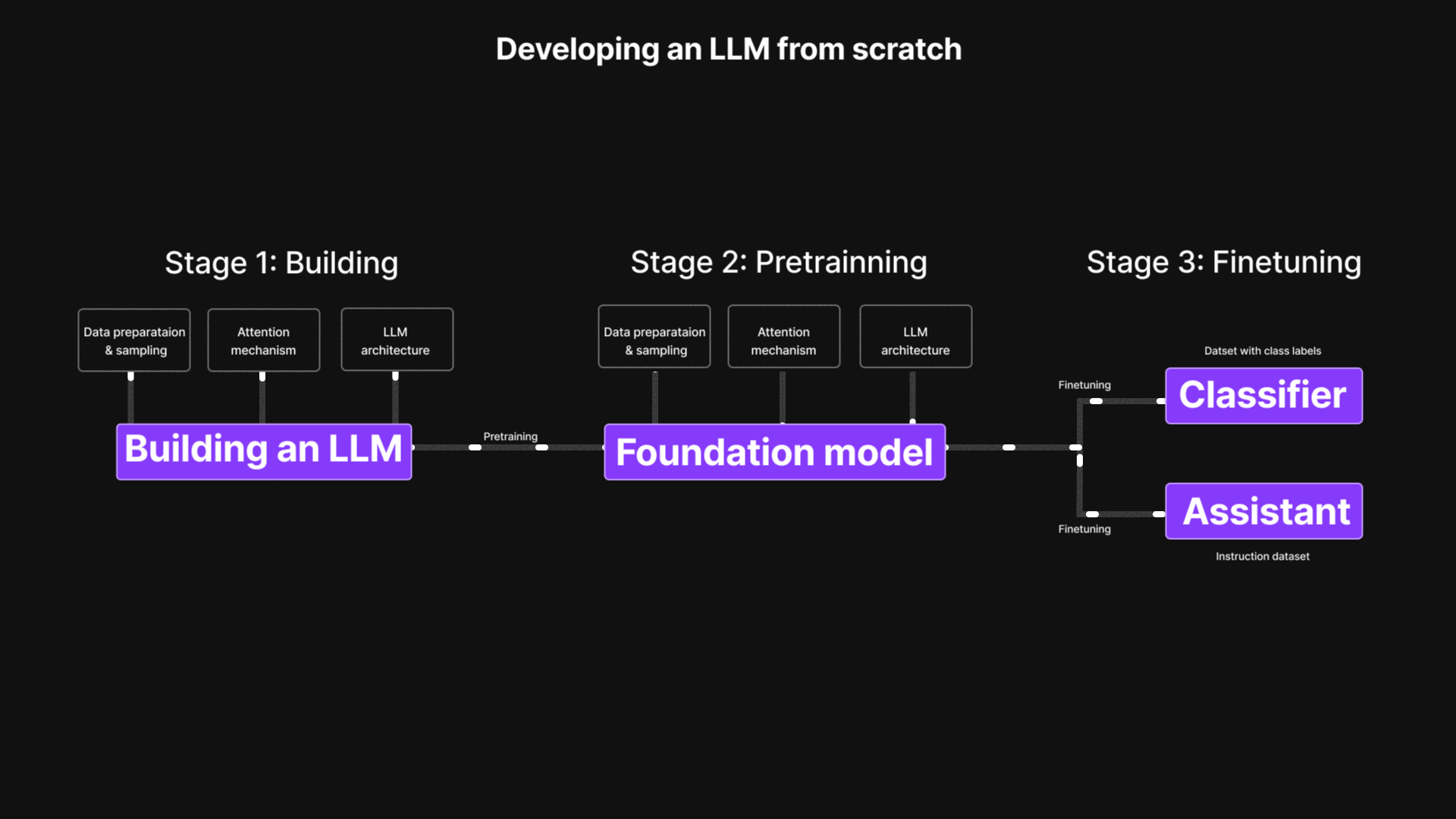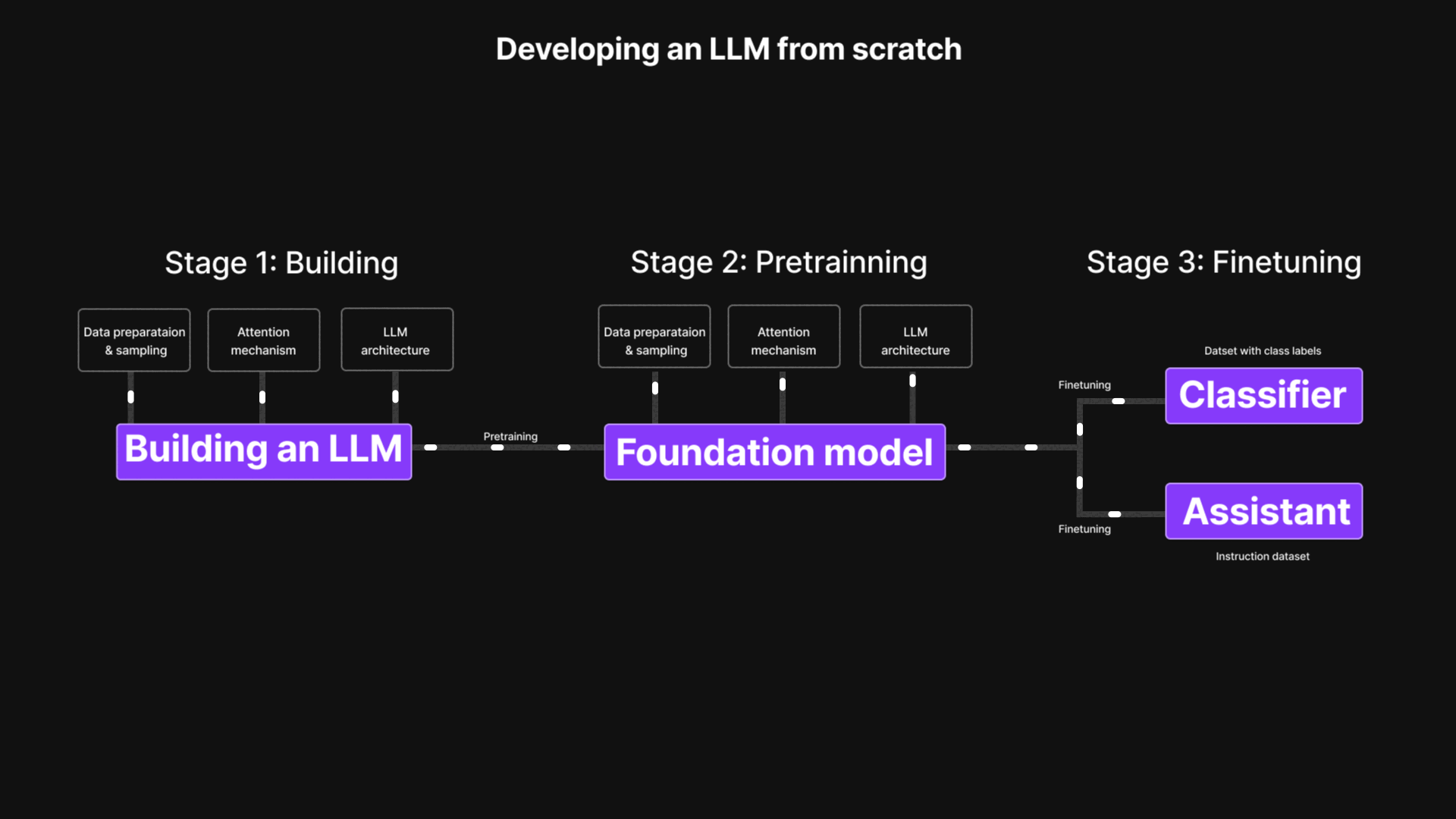
Large Language Model (LLM) from Scratch
Implemented a Large Language Model (LLM) from scratch, covering every stage from data preparation and model architecture to pretraining and fine-tuning. This project demystifies transformer-based models through hands-on code and experiments, enabling a deeper understanding of attention mechanisms and token prediction.
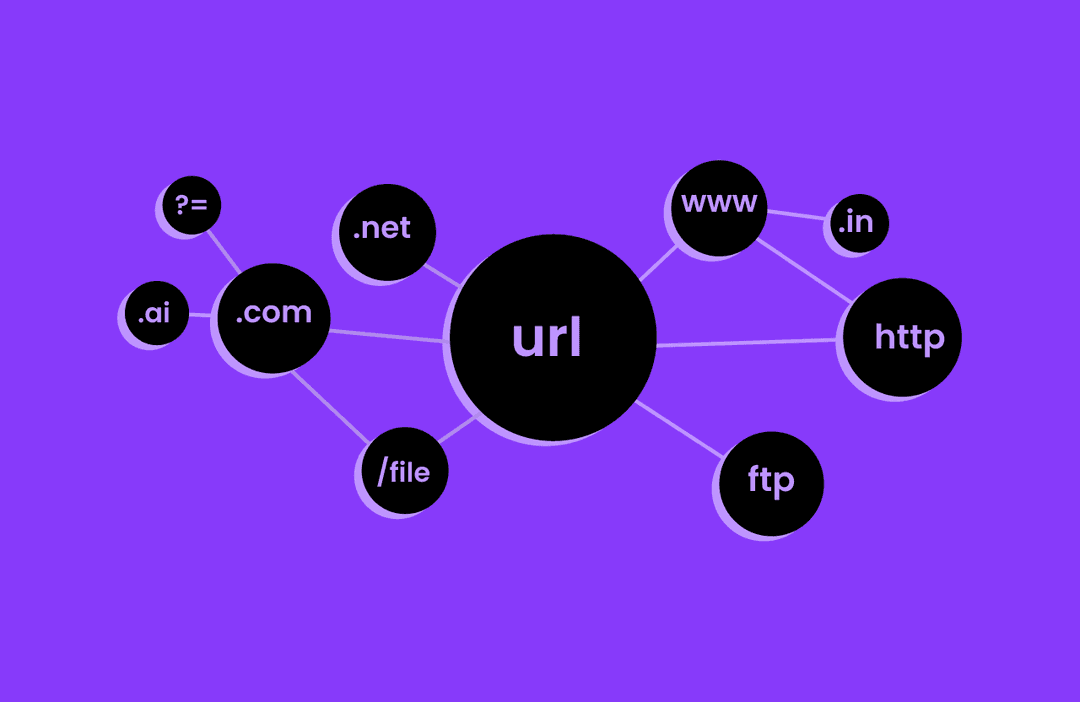
Network Security - Malicious URL Detection using MLOps
Developed an end-to-end MLOps project to detect malicious URLs using XGBoost. Integrated robust pipelines for data ingestion, model training, deployment, and monitoring.
Latest Blogs
Loading blogs...
Some of My Lectures

A visual guide to Word Embeddings
Jul 9, 2025
Dive deep into the fascinating world of word embeddings and discover how computers transform text into meaningful numbers!
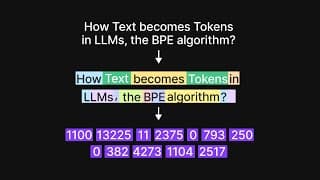
A visual introduction to tokenization in LLMs | Byte Pair Encoding Algorithm
March 13, 2025
In this video, I have explained tokenization in Large Language Models (LLMs) in a visual manner.
Skills
Get in Touch
I love connecting with people doing interesting work in deep learning. Message me on LinkedIn.
Follow and DM me on Twitter, that's where I'm most responsive.
Or just email me: mayankpratapsingh022@gmail.com